"Stochastic entropy production arising from nonstationary thermal transport", Ian J. Ford, Zachary P.L. Laker, Henry J. Charlesworth. Phys. Rev. E 92, 042108 (2015) (arXiv)
PostDoc Research
My post doc has focused on fundamental research in deep reinforcement learning. Our first paper, PlanGAN, looked at using a model-based approach for solving multi-goal, sparse reward environments. For a number of simple robotics environments we found that this significantly outperformed the state of the art model-free algorithm (Hindsight Experience Replay) in terms of sample efficiency.
In our second work, we created a number of challenging dexterous manipulation environments that existing reinforcement learning/trajectory optimisation approaches are unable to reliably solve. We then introduce a new trajectory optimisation algorithm that performs significantly better. On the particularly challenging PenSpin task (see video below), we combine imperfect demonstrations generated via trajectory optimisation algorithm with reinforcement learning. This allows us to achieve significantly improved performance, effectively solving the environment.
PhD Research
My PhD has mainly been about studying simple models where it may be useful
to apply the principle of "future state maximization" to make a decision. This principle is
essentially a formalization of the idea that all else being equal its best make decisions so as
to maximize the number of possible future states that you can access, i.e. to maximally keep your options open.
The motivation here is that by doing so you are preparing yourself for the widest range of potential futures and so in
some sense remaining maximally in control of your future environment. There have been two main attempts to formalize these ideas:
the empowerment framework which does so in the language of information theory and
the causal entropic forces which takes a more thermodynamic approach.
We have looked at some simple applications of this principle to small discrete systems as well as a simple one dimensional continuous system (both to be published soon) but the
primary application has been to a model of collective motion.
Intrinsically Motivated Collective Motion
Check here for the code implementing the basic model.
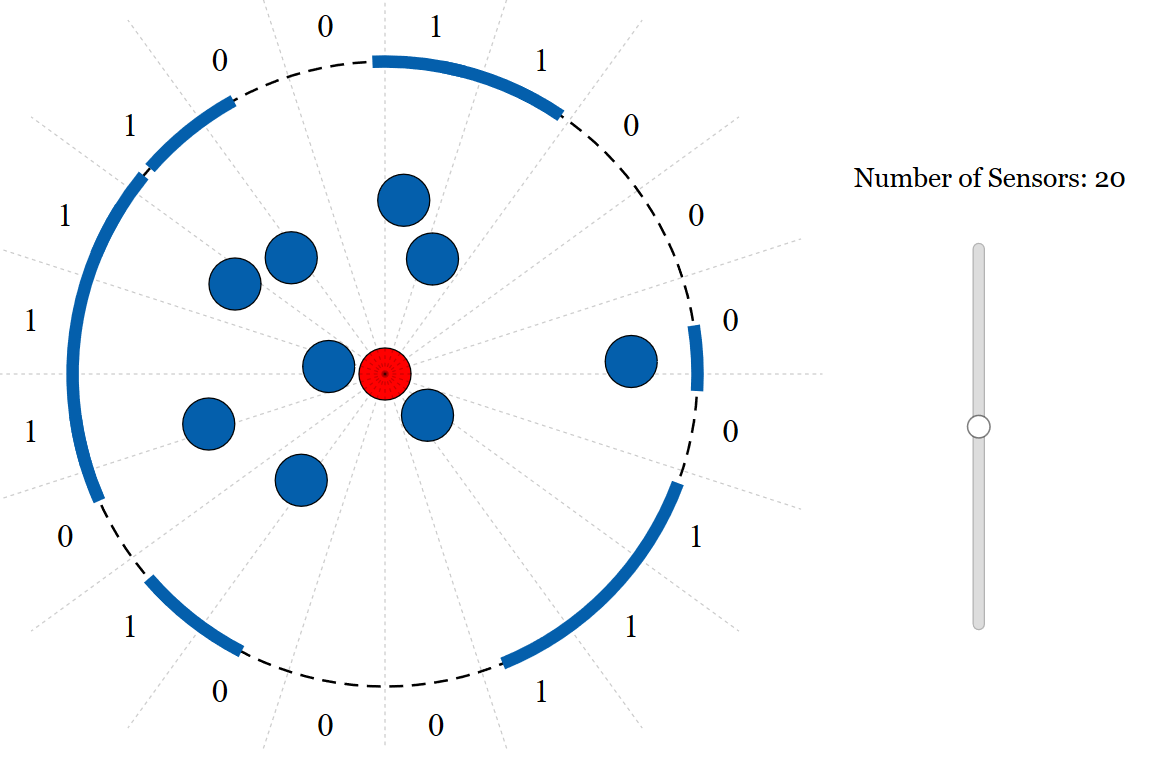
The basic idea is to directly apply the empowerment framework to a group of agents equipped with simple visual sensors. Technically this means each agent
makes a decision to maximize the channel capacity between its available action sequences and its possible future visual states at some later time. In
the case when the environment is deterministic (i.e. where every action leads to a definite next state) this measure reduces to maximizing the number of
possible visual states that are accessible at the future time horizon we are considering.
To apply the empowerment framework in a simple way the visual states need to be discrete. In our model we define the visual state in terms of the projection
of the other agents in the surrounding "flock". That is, each agent's field of view is divided up into a number of sensors, we take the projection of the other agents, and then if
a sensor is more than half full it reads a 1 otherwise it reads a 0. To visualize this I made an app in D3.js (click the image below):
Again to keep the model simple and apply the empowerment framework we need to use a discrete number of actions that each agent can take at each time step. We choose to allow for moving
straight along its current orientation at speeds v_0, v_0 + dv or v_0 - dv as well as reorientations by +/- dTheta. To make its decision, at each time step each agent performs a "tree search" of possible future states
and counts the number of unique visual states that are available to it conditioned on taking each of the five currently available actions. The agent then chooses whichever action leads to the largest number of visual states in the future tree.
Of course to do this calculation the agents need to have a model for how the other agents are going to behave in the imaginary modelled future trajectories, and so to keep things simple we just say that they model the others as moving in a straight line at v_0 along their
current orientation. In the upcoming paper we also experiment with some variations of this. To visualize the tree search I made another app in D3:
In this app you can add/remove agents by double clicking and drag them around to move/reorient them.
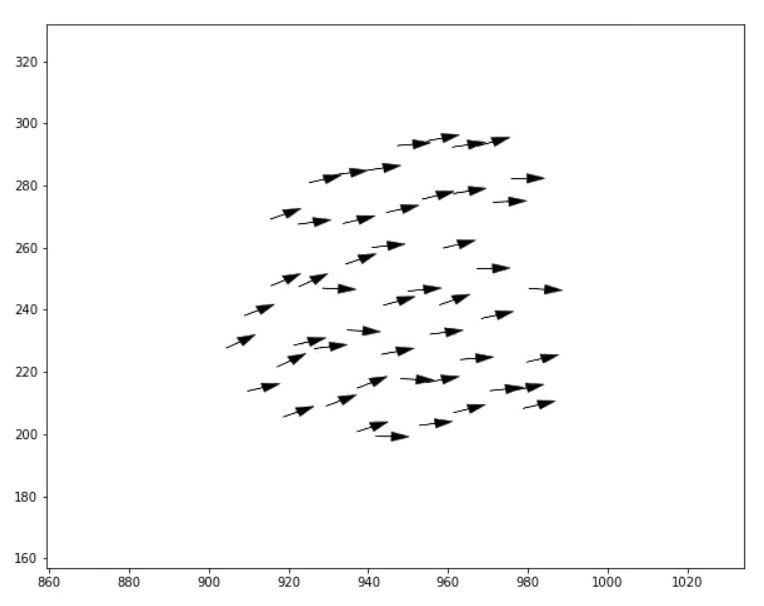
The application of this relatively simple principle leads to the emergence of highly aligned, robust and well regulated (in terms of density) collective motion without the need for any kind of nearest-neighbour alignment rules. Here is a video of a fairly standard set of parameter values (click the image to play):
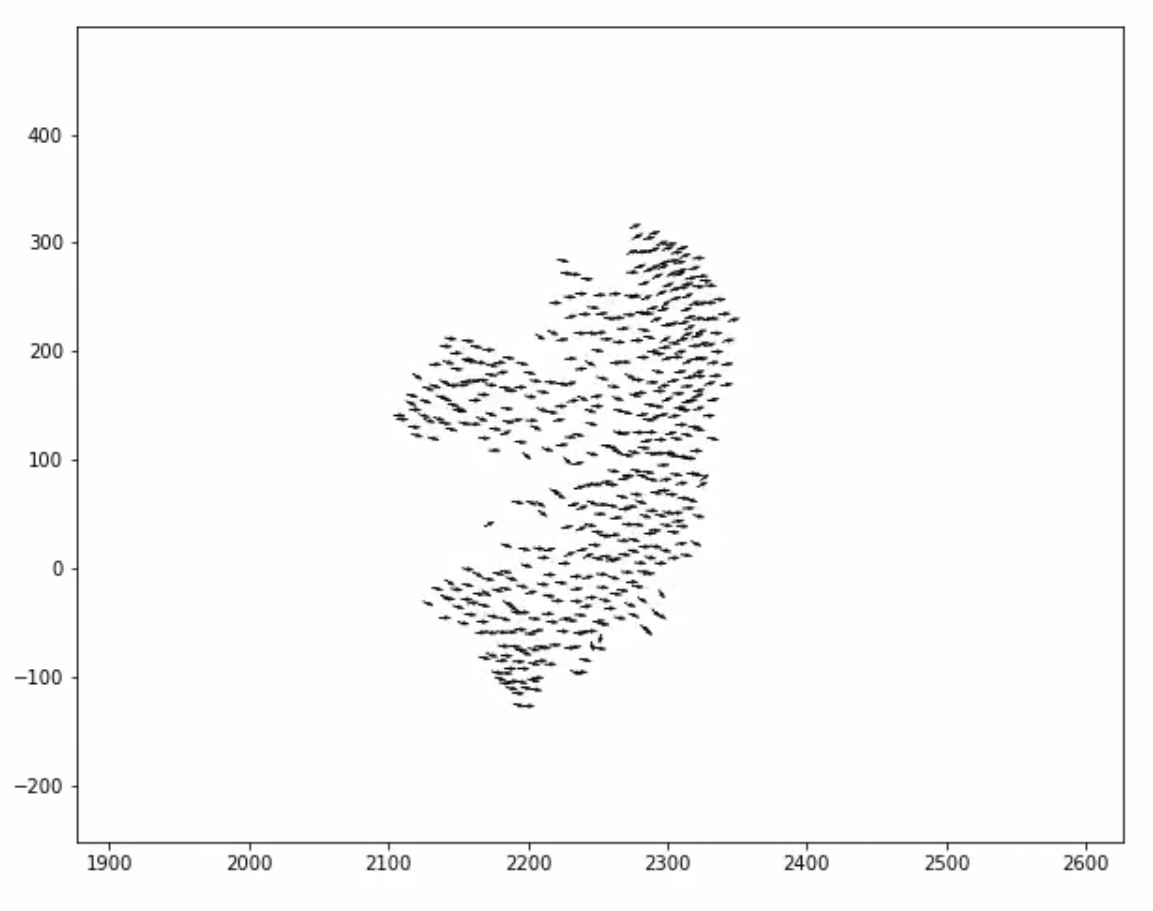
The results are even more interesting for larger flocks. Here we find that the dynamics which emerge are incredibly rich, with the flock's morphology changing continuously whilst still staying cohesive and aligned. The following video is for a version of the model where we use a more continuous version of the degeneracy in visual states, for N=500 agents (and was ran on the university's high-performance cluster):
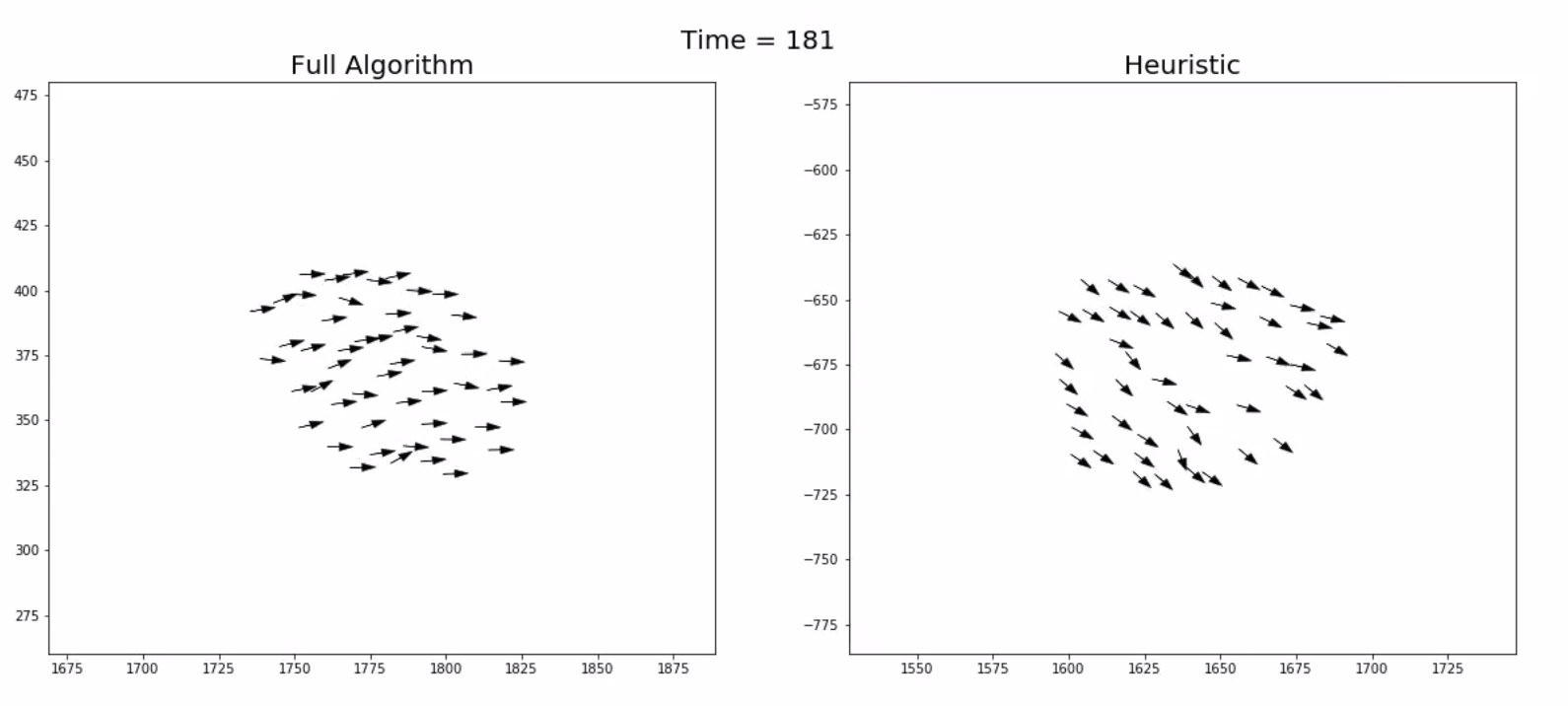
One issue with the full model is that it's quite computationally intense as it requires modelling a large number of future trajectories for each agent at each time step. It's also clearly not something that any real biological organism would be able to do. This motivated us to try and see if it was possible to train a neural network
that can mimic the behaviour of this algorithm but using only the currently available visual information that each agent has (i.e. without having to model future trajectories). To do this we run the full model recording the current visual state (and it turns out to be necessary to include the previous visual state too) along with the decision made
by the full algorithm which we use as the target for the neural network. Here's a comparison: